Most natural language processing and text mining systems have mainly been designed to operate on English language text. Yet, the majority of people online do not speak English, and as more and more people gain access to digital tools, there is an increasing need for tools that operate on other languages.
In some cases, it is feasible to develop new customized systems for specific populations. E.g., there are many tools that have been developed for te Chinese market. However, it is challenging to achieve this for all of the world's over 7,000 languages.
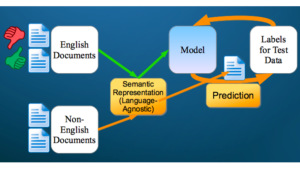
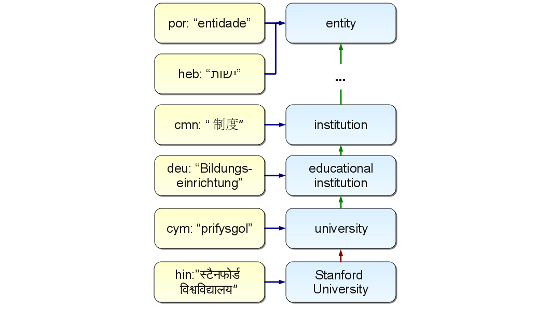
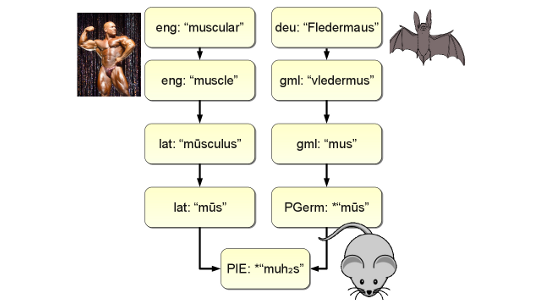
Cross-lingual NLP and text mining technology is an important alternative in such situations. The idea is to develop a system based on one or more languages for which many resources are available, yet be able to use it in many new languages by connecting their linguistic representations.
We are releasing the cross-lingual benchmark database from our SIGIR 2020 paper. In this benchmark, a text classification model needs to be trained on regular English training data, but is evaluated on documents that contain an automatically induced form of code-switching, i.e., many of the original English words have been replaced by non-English words.
Example:
Clorox Co disait it déclarés a two-for-one stock scission et autorisée a 10.3 pourcentage accroissement in la annuel dividende rate. The société disait la trimestriels liquidités dividende était boosted to $0.64 per partagez depuis $0.58 on a pre-split basis, exigibles August 15 to actionnariat of enregistrer on July 28. The société disait ce sera be la 21st consécutive annuel accroissement in la dividend. The additionnel partages résultant depuis la scission sera be distribuées on September 2 to actionnariat of enregistrer on July 28, la société said. Clorox is a fabricant of ménage épicerie produits et automobile nettoyage produits commercialisés in la United States et internationally.

For more information about the datasets and our cross-lingual prediction method, based on self-learning, please consult our publication:
Leveraging Adversarial Training in Self-Learning for Cross-Lingual Text Classification BibTeX arXiv Data
Xin Dong, Yaxin Zhu, Yupeng Zhang, Zuohui Fu, Dongkuan Xu, Sen Yang, Gerard de Melo (2020)
In: Proc. SIGIR 2020 (Short Paper). ACM.
Acceptance rate: 30%
Apart from the above, we have also developed a number of cross-lingual databases that facilitate cross-lingual NLP and text mining.